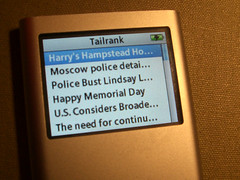
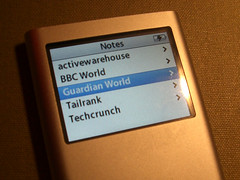
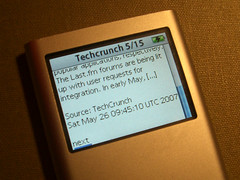
As recently mentioned I was looking for useful hacks for the iPod Notes feature, and as Google didn't turn up much of interest I started writing one myself. The obvious first application: an offline feed reader.
Turns out it's remarkably easy to do this. The Notes file format is basically text with some HTML markup, and even allows for links between individual documents. I.e., converting a feed into a series of notes and an index is pretty straightforward.
The harder part is the syncing mechanism. My requirements were: syncing has to work on a default OS X installation, it should be able to sync with my 2nd gen nano, and it shouldn't touch any other removable drives or iPods when you plug them in. launchd makes it easy to get notified when any new drive gets plugged in. But how do you make sure it's the right one?
Uniquely Identifying Removable Drives
It took me a while to figure out a way to uniquely identify the iPod -- there are a number of options with varying trade-offs. In the end I decided on a method that should work for many other removable drives, not just iPods. Took a while to get there though...
The most obvious identifier, the drive name, never seemed like a good option. Drive names aren't unique, and they can change. I don't want to reconfigure my sync software just because I decided to rename my iPod.
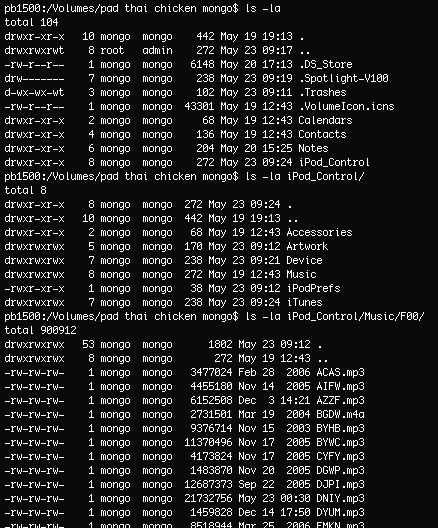
Next option: older iPod models had a hidden file /iPod_Control/Device/SysInfo that contained an iPod serial number, but since late 2006 that's no longer the case. Instead the iPod serial is now stored inside a hidden plist that you can request with a SCSI INQUIRY command -- which involves too much code for my taste, and seems a little brittle. People put a lot of work into reverse-engineering iPod internals, but it's still a game of cat and mouse.
Another option is to determine the pod's hard drive model and serial number, but I haven't found a way to do this with only standard OS X tools. smartctl -i can do it, but smartmontools aren't shipped with OS X. I'm suspecting there is a device file with that information somewhere, but couldn't find one. Add a comment when you know more.
Instead I ultimately decided on using Volume UUIDs -- they're sufficiently unique, they identify a specific partition, and they seem work for all kinds of removable drives (unfortunately not for my old MP3 player and memory stick.)
So if you combine this identifier with launchd (to get informed of volume changes) and rsync (to do the copying) and some Ruby glue you have a pretty decent syncing mechanism. And it's not even iPod-specific -- you could also use it to do auto-backups when you plug in a specific drive, and do other fun stuff with removable devices.
Current State
At the moment this application isn't much more than a collection of Ruby scripts and a launchd plist, not very user-friendly. I'm toying with the thought of creating a simple UI to configure sync options, and a basic plugin mechanism to allow to sync more than just feeds, but haven't yet come up with a method of creating an appealing interface that doesn't involve a lot of work... maybe you have some ideas. I basically want to be able to do it in an afternoon and be done with it. (Although I've written some Objective C and Cocoa code I'm not much of an expert.)
There also is no public SVN for this yet, but I'll create one when I'm sufficiently happy with the state of this.
I'm now testing this offline aggregator on the road -- seems like an excellent way to read news bits during my daily bus routine. (But it's actually not that easy to find sources that still work when you lose links & images...)
A friend just told me this: Turns out the MP3s on your iPod are completely accessible, even without any dedicated software. They're simply in hidden folders. Writable hidden folders.
Started browsing around for interesting hacks for the iPod Notes feature (are there any good offline feed readers for that? Or anything else of interest?), and found the Notes feature guide. Which contains this gem:
Felt like trying out virb's flash player embed. Not sure if they actually want you to do that -- after a quick search I didn't find a widget embed link, so I simply looked at their page source.
You need Javascript and Flash to see the player. Alternative link (with the same requirements): virb.com/dekstop.
Finally had a brief glance over Lev Manovich's "Database as symbolic form" (can't remember why I bookmarked it), was underwhelmed. Nobody who is familiar with the structures of either modern culture or technology will find much new ideas in there. (Granted, it's from 1998.)
But there was one paragraph that made me think:
As a cultural form, database represents the world as a list of items and it refuses to order this list. In contrast, a narrative creates a cause-and-effect trajectory of seemingly unordered items (events). Therefore, database and narrative are natural enemies. Competing for the same territory of human culture, each claims an exclusive right to make meaning out of the world.
Regardless of whether one agrees with all of the assessments in that paragraph (it's easy to disagree with several) the core of it seems to be the observation that "databases" as well as "narrative" are simply different ways to structure information. Like in that unfunny Apple UK commercial: You can tell a story with videos and a slideshow, or with pie charts.
Of course these methods to structure information have different characteristics in the way they treat it: a story is often most interesting in its evocative effects, in the underlying narrative that is not actually put into words. Whereas a "database" (e.g. a tagging system) is usually most interesting because it not only describes, but allows to rearrange.
If at this point you feel the need to call this difference "connotation vs. denotation" and be done with it you're wrong however, Mr. Straw Man. Both are obviously powerful tools, serving different purposes.
The interesting bit to me is simply this: We're gradually finding out new ways to structure information that in certain contexts can be much more powerful than the old ones. This is why people use Flickr and stopped making photo albums. This is why YouTube is so interesting, even if most of its content is still shit. This is why we now use del.icio.us to read up on trends in technology and stopped reading magazines. Why digg might replace certain parts of CNET.
Story (to keep in line with Manovich's annoying decision to talk about database) is simply not the most efficient method any more to convey any kind of information. In the olden days people maybe wrote poems and songs to transport political news. Today we email links.
None of which are new ideas I guess, but hey it's 3:08am where I am, and you're reading this on a blog, so what can you expect.
Bought some cheap second-hand gear from a friend of a friend, just did a quick test recording. Two distortion pedals (one left, one right) with empty inputs (dangling cables.) The second recording features an additional stereo compressor.
I received some complaints about the last batch of mp3s -- these are much less harsh, I promise :)
Will definitely play around more with this, but I need more cables. And microphones.