Yesterday night I returned from Datenspuren 2006 in Dresden, a conference on privacy and technology organized by the local CCC. This was both the first time I was in Dresden, and also the first time I attended the Datenspuren conference, so I was curious to see both. Short version: I'll probably come back next time.
Read on for info on the current state of communications data mining and visualization, new chip-based identity systems in Germany, and other stuff I found interesting.
Full entry
I decided on a whim to mirror "Network Forensics Evasion: How to Exit the Matrix" on my server, at least temporarily. This fairly elaborate text describes a number of technical (and some non-technical) means of hiding and obfuscating your "data trails". While this traditionally has mainly been a concern of crackers and dissidents, it's of increasing interest to the average consumer.
I just started reading, so I can't say much about the quality of the document.
The text comes with a disclaimer:
I try to be as operating system agnostic as possible, providing information for Windows, Mac OS, and Linux. However, novice computer users who are uncomfortable tweaking settings, editing configuration files, and occasionally using the command line probably will struggle with much of the material regardless of OS [...] Due to the open and readily customizable nature of the system, the Linux material probably will be the most well developed.
[via fukami, via jot*be]
update 2006-06-02 -- new version 0.10.3 (thx to noshow)
Download
I just came home from an interesting discussion: the "tesla salon" had a session at club Podewil with the topic "verwertungsgesellschaften im digitalen zeitalter" (roughly: "collecting societies in the digital age"). The event was organized by Radio 1:1.
They had a well-chosen group of participants: Tim Pritlove in his role as podcaster and "discordian evangelist", Julian Finn as a representative of FairSharing (i.e., the culture flat rate), and two netradio guys whose names I haven't written down and who sadly aren't mentioned in the program.
Read on for a rough recapitulation of some of the issues raised, new rants against GEMA, and my prediction for the ghetthoization of mass culture.
Full entry
I've been silent for a couple of weeks now for a reason: I just submitted my finished diploma thesis (finally!), which meant I had little time for anything else. (Title of the thesis: "Using Evolutionary Algorithms to Explore the Sonic Spectrum of a Software-based Additive Synthesizer", iirc.)
I'm now recovering and looking forward to my newfound freedom (but it's not over yet, there's still a verbal exam coming up).
To rephrase: Don't expect many updates in the upcoming weeks either, I'm chilling.
I finally found a good test case to compare YARV's execution speed with the plain ruby interpreter -- and the results are quite satisfying.
The script I benchmarked reads and parses 3.300 small XML files, extracts data, and writes the result to a tab separated file.
Read on for the results.
Full entry
Last April, nearly exactly a year ago, I bought my first Mac (a 12" Powerbook), and after a while that became the only machine I use. There are at least two working PCs in this appartment that by now are only used as storage medium or by visitors.
This last Wednesday I had to send the Powerbook in for repair (with a broken battery and CD drive), so I had to dig out the old Thinkpad as temporary replacement. And now I'm surprised at how fast habits change -- up until last year my main machines were always running Microsoft OSes, yet I can't bear the thought of having to go back. I even briefly pondered getting a Mac mini as temporary work environment, and if I had the money I'd probably have bought one.
The last days back on Windows have been an eye-opener on several levels.
Full entry
I've just implemented article feeds for this blog, which is a great feature for everybody who wants to track comments on a particular article, or for people who want to track updates on articles that are too old to be included in the blog's main feed.
Originally I simply wanted to add a comments feed for each individual article -- currently I only offer a single combined feed of all comments, and that's usually not what anybody is interested in. Why should you suffer from receiving many irrelevant entries if you're only interested in comments on a particular article? And as I'm notified of new comments via email this comments feed isn't even of much use to myself -- I'm subscribed to the combined comments feed, but by the time NNW updates it I've already read the comment.
Then I just saw how Sam Ruby implements article feeds for his blog, Intertwingly: the first feed entry is the article itself, and all consecutive entries are comments on the article. And I think that's a really great idea: Because if you're interested to read comments on an article you will probably also be interested in reading updates on the article itself. And it makes for a more complete feed reading experience: now an article's feed contains the same information as the article page itself, it's just two formats of the same data.
Article feeds are referenced on two locations of every article page: For human eyes there's a short text between an article and its comments that links to an article's feed; and for aggregators, feed bookmarklets and other machines every article page now has a <link> to its feed representation (look at the HTML source of an article to see this).
I've also made some changes to the blog's main RSS feed: It now contains multiple categories for articles, and also the full author name on each article.
The new feeds nearly validate: The RSS 2.0 spec requires the <author> field to contain an email address, and I've chosen to only insert a name. This has been true for the old comments feed for a while, and is an issue a lot of feed authors have with the RSS 2.0 spec -- in an age of sophisticated spam bots nobody in their clear mind chooses to publish email addresses in the clear any more. (Which is also why I've decided to drop MovableType's mandatory email field for comments a long time ago.)
I then updated the blog's OPML file to also point to comment feeds; and with a little tweaking the OPML finally validates...
Let me know if there is a desire for category feeds as well.
Update: 2006-03-20 -- I've migrated the old comments feed from RSS 0.91 to RSS 2.0. Am now thinking about using Dublic Core's <dc:creator> as a replacement for RSS 2.0's <author> property.
Update: 2006-03-20 -- Oh, and I'm thinking about adding search result feeds -- which might be even cooler than category feeds. We'll see.
flOw has everything I wish from a good game -- it's simple, yet it sets a great mood; it simply feels good to play it. And although the visuals are abstract it's a very organic game. There is a learning curve, but you're flexible in your approach to playing. And if you get the download version you can also play fullscreen.
The game's only flaw is that you soon reach a point where playing on makes not much sense, because you've eaten all there is to eat. Not being an active gamer I needed a couple of attempts to get into the "flow", and so my first games were way over an hour -- after playing for more than a week I average at about 30 minutes.
As the game is under active development I still have a little hope that Jenova Chen and crew will add a procreation feature (or what gamers like to call "respawn"), and thus stretch the playing time from 30 mins to endless. And maybe one of these days I'll figure out how to activate the cheat mode on my German keyboard...
flOw is also a great backdrop for podcasts. Recommended podcast of the day: Christopher Lydon's Radio Open Source (which, despite the name, is not actually about software -- it's talk radio, and very good at that).
Links
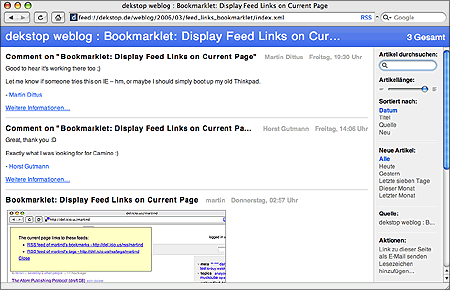
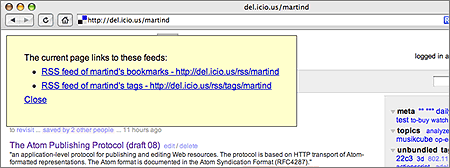
I found an older article on the Google Reader blog where they post a great bookmarklet: It displays feeds referenced by the current page and allows you to preview them in Google Reader. Convenient for their users, and a great building block for a more generic tool.
I've modified their code in a number of ways -- the most obvious change is that the bookmarklet-generated links will point directly to the respective feed URLs, not to a Google Reader preview page. Then there are some cosmetic changes (I didn't like their choice of generated markup), but not much else.
Here's my version:
Show all feeds
I'll be using this bookmarklet a lot -- Safari's handling of the <link>-tag is not very convenient, and I've just about enough of manually looking for feed links, be it on the page or (frequently also) in the HTML source.
Chris Wetherell of the Google Reader team states in their aforementioned article that this will not work in IE6 with SP2 -- I haven't tested on any IE. FF and Safari work fine.
Update: 2006-03-16 -- made some small changes to the code.
Update: 2006-03-17 -- fixed a text color bug on some sites. Slightly shorter code.
Update: 2006-03-19 -- fixed another text-related bug on some sites. Some refactoring -> even shorter.
Update: 2006-05-08 -- Pascal Van Hecke pointed to this article in his own blog, and one of his readers states in the comments that it's also working in Opera.
Update: 2006-06-22 -- Horst Gutmann uses the bookmarklet to work around a usability issue in Opera 9.0 (see forum discussion)
Update: 2006-11-18 -- Marjolein Hoekstra extends this into an OPML Auto-discovery Bookmarklet, cool idea! The accompanying article also has a great explanation of the process of feed discovery, and on how to make your OPML auto-discoverable, so it's definitely a recommended read.
While reading this:
Google built a feed platform that is freely available for any user with a Google account.
... and re-reading this:
The data technologies powering Google Reader can easily be used and extended by third-party feed aggregators for use in their own applications.
... it struck me:
- centralized aggregation, decentralized delivery and UI
- the hardest part in a reader (IMHO) is aggregation, because it offers a lot of pitfalls with little reward for making it "just work"
- more interesting: the visible stuff
- solves bandwidth issues for everybody
- solves stability issues for everybody
- saves costs for the developer/hoster (these kinds of applications are way more resource intensive than the typical blog software)
Note that this is completely in line with the software industry's current trend:
- there is no money to be made in basic infrastructure: someone already does it better, and for free
- now every web developer can create their own feed reader within an afternoon.
- which of course means (repeat after me:) software is a commodity.
To each his own
Custom software is where it's at. The small projects developed with minimum effort, for a small set of uses or users, possibly active for only a limited time until you don't need it any more, or until something better comes along.
Which also means it's important to make migration between software solutions painless. Say, as painless as exporting and then importing an OPML file.
Or, say, as painless as simply logging in.
Because when the underlying infrastructure for all those little feed readers is provided by Google there is no need to migrate any data.
(And, of course, this all also ties us closer to the data monster.)
Now I'm seriously considering scrapping the little work I did on a Ruby feed aggregation infrastructure. There's cooler stuff to do than thinking up flow charts of HTTP error states.
Or is there?
Hm.
Related Articles