On friday I received a message via my contact form that looked a lot like the comment spam that blogs normally get: with a generic reference to my site content ("Well done very nice page" etc.), and a link to what obviously looks like a spammer's site. Signed with a name and email address. Unfortunately my web hoster's logfiles weren't accessible (again), so I couldn't check whether this was a manual "attack" or from a bot.
Well the logfiles just started working again, so I had a quick look and now I'm a bit worried. Look at the (abbreviated) excerpt from the Apache access logs:
[02/Dec/2005:15:40:42 +0100] "GET /weblog/archive HTTP/1.1" 301
[02/Dec/2005:15:40:42 +0100] "GET /weblog/archive/ HTTP/1.1" 200
[02/Dec/2005:15:40:43 +0100] "GET /contact/ HTTP/1.1" 200
[02/Dec/2005:15:40:43 +0100] "POST /contact/index.php HTTP/1.1" 200
In other words, this either is an incredibly fast surfer or what looks very much like a fully automated bot. These are the only requests made from the spammer's IP address on that day, which means this bot is also very efficient.
For people unfamiliar with Apache logfiles I'll paraphrase the above:
- First the bot requests an arbitrary page, probably the result of a web search. The request is answered with an "HTTP 301 Moved Permanently" response from my server, which tells it to retry the request with an added slash.
- The bot abides and requests the correct page.
- The next request: my contact page, where there is a form to write me a message.
- And still within the same second the bot finds and submits this form with all fields properly filled in.
I'm not so much irritated by the fully automated fashion of the affair, after all this is not rocket science; but what threw me off was the fact that it went directly from the archive to the contact page when on the same page there are dozens of links to blog pages with standard MovableType comment forms.
Sweet Baby Jesus. If this catches on I might just as well post an email address. Blog comments can be shielded with comment spam plugins, and email filters are amazingly efficient -- but I don't feel like implementing the same technology for my little contact form. Crazy times.
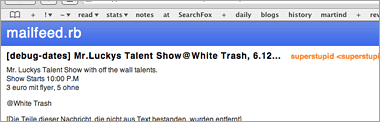
A friend has asked me for a way to read email newsletters from within his feed reader, and after some digging around I found it's straightforward enough to access POP3 mail from within Ruby, so I created mailfeed.rb.
mailfeed.rb is a Ruby script that generates an RSS 2.0 feed from the content of an email inbox. This can e.g. be used to read email-based newsletters from within your feed reader. (See also: MailFeed for PHP, pymailfeed for Python.)
It's really a pretty simple script, so there are a number of caveats -- e.g. there is no limit on the number of feed entries displayed, and there is no local caching of mail content (the script will always download the full content of your inbox, which can take a while if you receive large attachments or images).
Also be aware that feeds as communication channels are usually not as private as email. This is especially true if you use a web-based feed reader like Bloglines or SearchFox: your feed might show up publicly in their search results or directories. So I recommend that you either only use this script on a dedicated mail account that doesn't receive private mails, or that you at least configure your web server to require authentication to access this script, and read the feed with a locally installed feed reader such as NetNewsWire or FeedDemon.
The script's comments have installation instructions and more detailed information.
Any feedback is welcome. Tell me if it is or isn't working for you, or if you have ideas for improvement.
Download
The Fahrplan (schedule) for 22C3 (the Chaos Computer Club's Chaos Communication Congress) is now online, along with the blog, Flickr pool, wiki, and podcast. So I started to browse and collect lectures I'd like to see, and then realized that like last year I have a scheduling problem...
I'm still trying to find out how I can use the iCal calendar file for things beyond looking at dates in iCal. Apparently the data is imported read-only, which means I can't annotate; and it would be great to find ways where iCal can help you schedule your congress experience. There of course is iCalendar for Ruby, but the gem version only throws exceptions when I try to load the data.
Anyway.
Read on for some recommended sessions, and a brief commentary on last year's 21C3.
Full entry
There are more and more details emerging about MIT's/Nicholas Negroponte's $100 Laptop, and the more is revealed the more exciting it sounds. Kofi Annan has just unveiled the first prototype at the World Summit on the Information Society in Tunis, and there are a lot of other important people involved (apparently Rupert Murdoch is among the sponsors).
This project is a rare (yet well-publicized) example of individuals at the right places joining force to not only develop a technology that might change the world, but also doing so openly and without financial merit for themselves. Negroponte puts it best:
I'd love to see industry compete with us and come in at lower prices. To us the best thing we could do is to have people take the idea, replicate it, copy it, and make it cheaper. That would be to us a dream come true.
This excerpt from Ars Technica's coverage of the accompanying press conference nicely sums up some of the technical details, and provides hints towards the technological inventiveness involved in such a product:
Mary Lou Jepsen, CTO of OLPC, provided just a few tantalizing tech bits about the display technology, as well as stating that the motherboard will be mounted beneath it. It will not be an LCD, but rather some kind of LED technology that will make a modified portable DVD display of 480x234 produce an image equivalent to 800x600 with a pixel density of 150 dpi. Power usage is apparently magically low too, with Negroponte claiming that "one minute of cranking will provide 30 minutes of use," though this did not factor in wireless usage. Presumably, 802.11 will be used in conjunction with mesh networking for ad-hoc connectivity from a central access point.
It's going to be exciting to watch this project evolve, and to see it deployed. And it's also going to be interesting to see how technology of this kind changes our life back home in the "civilized" world; the laptop itself will not be for sale, but good (technical) ideas are valued everywhere. I'd certainly like a hand crank for my own laptop sometimes...
Update: BoingBoing links to a new Wired article on this topic, with an interview with Nicholas Negroponte. Best quote:
Wired News: So you're shipping this with development tools installed?
Negroponte: Yes. Absolutely.
And the piece also reminded me that I'm really looking forward to my first laptop where the main storage device is on a chip. In several ways, this low cost computer is ahead of the much more expensive technology we already own.
There is an interesting post on Slashdot pointing to an article by Ben Meyer, about the concept of a Type Manager as opposed to the oldschool concept of a file manager. Quote from the Slashdot introduction:
In the past few years many of us have been introduced to a new type of application, the Type Manager. Most of us are familiar with iTunes, but there are many other Type Managers out there that are gaining market share and a rabid fan base of users such as digiKam and amaroK.
...
After creating a list of all the traits of a Type Manager I was able to define exactly what a file manager should be and discovered that there are in fact many partial Type Managers out there now that implemented only half of what makes up a full Type Manager.
I only skimmed over the actual article (will read it later though), but the concept seems intuitively logical and intriguing. It is true that we moved away from having a single database of files, and from having the file manager as our means to manage these files. An average system today has several of these content-type-specific databases, spreading over datasets as diverse as email, audio, photographs, sourcecode, and others.
 |
TextMate has some Type Manager properties as well --
but it's certainly not very evolved. |
We often don't really access individual files via file managers any more when we want to work with them, but via targeted interfaces. I use my development environment as much as an entity browser for my projects as I use iPhoto to handle images. Often it isn't even possible to load individual files any more except from within a Type Manager; in the case of email files are stored in proprietary databases, and in the case of iTunes (and similar audio/media environments) it's much more work to find individual files via a file manager than via a dedicated application.
I also found it interesting that most of the Slashdot readers commenting the story instantly refuted the notion of Type Managers. I usually love to read Slashdot comments to verify factual contents of a story, and it's often more interesting to read the comments that to actually RTFA -- but in this case they clearly got it wrong.
I think it's an intriguing thought, and the reasons for and consequences of this emerging type of applications might not be clear at once (they're certainly not yet clear to me), so it's a great idea to play around with. And it's no surprise that (as usual) Apple 'got' it first.
Ben, don't let the flames discourage you. I think you're onto something big.
There is another wave of comment spam coming to my site -- the new variant, where they don't post their own URLs any more, but either URLs that aren't active yet, or URLs of blogs that have already been infiltrated with comment spam.
The rationale behind that: I'm supposed to not be put off by the usually offtopic comments and broken grammatical structure and leave them alone, which increases the PageRank of the URLs posted, which in turn increases the PageRank of all pages these URLs link to. Comment spam by indirection.
Here's the kicker: they are already putting quite some effort behind this, but make the mistake of reusing the same couple of URLs over and over in their comments. That, of course, can easily be caught by MT-Blacklist (which, btw, is a godsend for someone like me who is still using an ancient MovableType version. Thanks to Jay Allen for keeping the downloads up, seriously). During the last 24 hours, 45 comments have been caught linking to the same 5 URLs over and over.
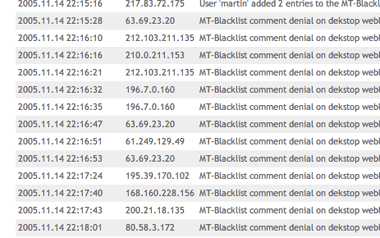 |
Excerpt of my MovableType log. Note the varying IP addresses of comment sources -- their comments all link to the same URLs. |
I can't imagine how it'll be when the next generation of comment spam tools appears, and they'll have unique URLs and unique text for each new spam comment they post. The only other line of defense we have then, it seems, is referer checking (which spammers already can bypass easily), and IP blacklists (which are of questionable value, and are also being bypassed already by distributed spam bots). Oh yeah, and captchas...
I'm looking forward to daily manual filtering again. My only hope is that spammers will learn to distinguish between deserted blogs and blogs that are actively maintained, and will eventually leave the latter alone.
CollaborativeRank is an interesting service that builds on the del.icio.us database. They provide bookmark search, a ranking of popular bookmarks, and they attempt to find connections between the things people store in their del.icio.us account and their area of expertise. It's the last feature that I find the most interesting. While it disguises as a ranking of users, its main promise is that it could help you find experts on arbitrary fields.
During the last couple of weeks I've been watching my rank, and while I wouldn't necessarily agree with its estimation of my expertise it's still interesting to watch.
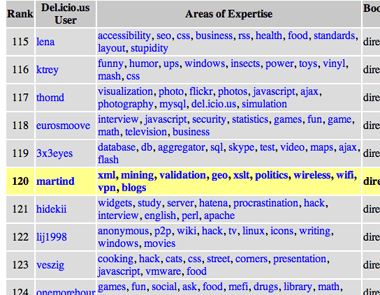 |
At the time of writing I'm 120th on CollaborativeRank's list of del.icio.us users. |
Read on for an analysis of CollaborativeRank's methodology, some of its flaws and a short list of (tongue-in-cheek) tips on how to abuse their system to get a better ranking.
Full entry
Just read in a comment by Esteban Kozak that SearchFox RSS uses both "attention and community data" when determining the value of an article, which means that some of the weird effects documented earlier might be a result of other people's behavior, as opposed to my own.
Read on for a hypothesis on the effects of group behavior and high-traffic feeds (which Esteban then confirms in the comments), and some recommendations for the SearchFox developers.
Full entry
In today's server logfiles: 13 requests from a host called "teamramrod.com". This is a pretty obvious movie reference, yet it made me curious enough to go check it out. www.teamramrod.com redirects to google.ca, but we can at least check the domain entry:
$ whois teamramrod.com
(... bla bla ...)
Administrative Contact:
Team Ramrod
Rodney Farva
51 King St.
Spurbury, ON
, CA
(519)5551235
()
farva@teamramrod.com
I thought this was rather funny.
I don't get it. Around the time I wrote about SearchFox RSS's "Topics I Like" feature I adjusted some of my reading habits (notably minimizing the consumption of web two-point-oh hype, and subscribing to more non-tech-oriented feeds), and the list of "topics I like" hasn't really adjusted to that. Maybe I'm too impatient, but I was presented with about 1.200 articles since last Wednesday and the list of "topics I like" seems rarely changed.
Read on for more details and a first analysis.
Full entry