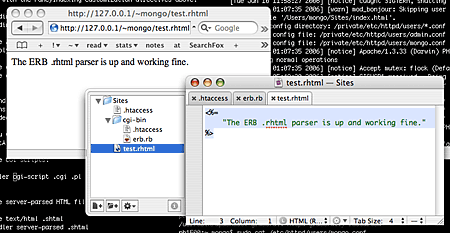
This documents how Apache 1.3 on OS X can be set up to serve .rhtml files using Ruby's ERB template system. Most of the required configuration is already described in Brian Bugh's article Using ERB/rhtml Templates On Dreamhost, but OS X's basic setup is conservative enough to require a little additional configuration.
However the real reason I'm writing this is that I additionally wanted to limit the handling of .rhtml scripts to my user account's "personal web sharing" directory (which maps to a tilde URL like http://127.0.0.1/~username/), and this isn't as straight-forward, so it took me a while to figure out the specifics.
The reasons for using the personal web sharing directory instead of the server root?
- It's more convenient. You can edit scripts without admin permissions.
- It's more secure. No need to manually chown/chgrp your scripts to make sure they aren't owned by root.
- Aside of that it's a matter of preference -- I like to have everything I'm working on in a subdirectory of my user profile. Easier to backup, etc.
So this article will describe two setups: first a global setup which enables .rhtml for the web server root, and which isn't much different to the setup described by Brian; and then a user setup limited to serve .rhtml only on a user's home directory.
Read on for a detailed description of the configuration process.
Full entry
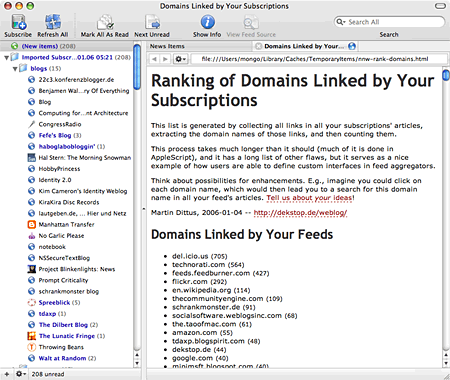
Recently there have been a number of requests for new ideas in the aggregator market, and as I'm constantly dissatisfied with my feed consumption experience (no matter the tool) I have lots of opinions on the state of aggregator software -- and even some ideas for improvement. I'll save the grand overview for later; because some things are better shown than told I thought a good start would be to show sketches of what I'd like to see in the next generation of aggregators. Here's Sketch One, which is kind of an accumulation of concepts, and which describes the basis of where I see aggregators going in the future. You've read it in the title: User-defined interfaces!
Read on for a description of what I mean by this, and for a downloadable example: an extension for NetNewsWire that parses your feeds for links, and then displays a histogram of linked domains, all within the NNW interface. And with lots of colorful screenshots.
Full entry
Just found out how to work around a major nuisance of GMail: the inability to select the low-tech HTML view as default interface. It's probably going to be old news for a lot of people, but it was new news to me, so I'll post it here for others to see.
Background
I've been using GMail as a secondary email provider for a while now, and while I like that its Javascript-based interface affords you speed improvements and other nice enhancements I can't get used to a major drawback: you lose the browser's history function, at least in Safari.
Others might not care much about this (otherwise GMail wouldn't be as popular as it is, I suppose), but to me it's one of the reasons why GMail will never replace my main email client, and why I feel uncomfortable using it -- Cmd+Left (and Alt+Left on Windows, and the corresponding mouse gesture "click right+drag to left") is hardwired into my brain, and it just comes natural when I want to return to the previous page. Alas, when using the GMail "standard view", history->back will simply lead you to a white page.
Now GMail has an alternative HTML interface, with most of the interface slickness removed, and with an attention-grabbing banner at the top of the page (see screenshot below) -- but as I'm using their service for about 10 mins a week max I'm willing to endure this for the sole fact that the HTML view has a working browser history.
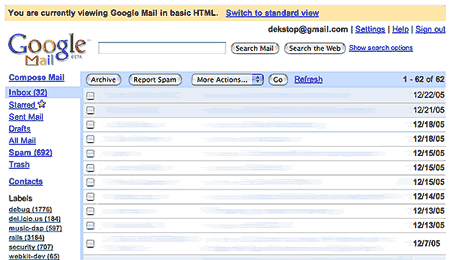 |
Google clearly wants to make it hard for you to pass on their innovations -- note the unobtrusive banner at the top of the page that asks you to Please, Please Click On This Link To Get Back To Wonderland. |
Getting Closer
I was doing some mail maintenance this morning, and as I had Javascript switched off logging into GMail presented me with the HTML view. After finishing with my weekly routine I got curious what would happen if I switched Javascript on mid-session, but found that it did nothing -- some web interfaces do user agent capabilities checks on every page request, but GMail doesn't seem to be one of those. Which meant it was keeping state somewhere.
There are a number of ways a web application keeps session state information -- usually it's on the server, combined with a client-side cookie. But the most obvious location to look for state information is always in plain view: a page's URL.
And indeed, as it turns out there it was.
The Workaround
If you know that you'll want to access GMail using its HTML view, and you're too lazy to switch off Javascript before you log in, simply open GMail using this URL:
http://gmail.google.com/gmail/h/
Yeah it's longer than gmail.com, but c'moooan -- who types URLs manually nowadays. Bookmark it, create a Quicksilver trigger for it or whatever else suits your fancy. In Safari, every bookmarked URL shows up as a suggestion when you start typing into the location bar -- so even if you don't want a GMail bookmark wasting space on your bookmarks tool bar, GMail is just a Cmd+L, gm<return> away. And I'm sure you have dozens of even more effective ways to quickly access a specific URL, so I'm probably wasting space here.
Update -- this seems to work as well:
http://gmail.com/h/
And as stated before, the HTML interface of course removes a lot of the reasons that make GMail attractive, but as a very occasional GMail user I'd rather lose new features when it means I can keep using the site in a way I browse all other websites. And maybe you work the same, and in that case I was glad to help... ;)
Safari is Getting Old
While cross-checking this I just found that Google fixed GMail's browser history in Firefox -- you can actually access GMail's browser history from within the standard view, and it's quite fast. Just one more reason why Safari is more and more feeling like an 'alternative' browser, with Firefox having the better features (notably Greasemonkey, and user-created extensions that don't mess around with function lookup tables).
Wonderful how the software you choose still defines your Internet experience, mostly in very subtle ways. And despite all efforts to standardize web technology this won't change, ever. Web development is and has always been a mess.
But then what isn't.
Another 22C3-related Ruby script: I thought it would be neat to convert the list of Weblogs writing about 22C3 into an OPML file which can then easily be imported into your favorite aggregator. Ruby to the rescue.
The script scrapes the Wiki page (or rather its export format version) and iterates over the table of blogs, adding a feed URL of each blog to the OPML outline. Look at the code for further information.
Of course you can also simply get the exported OPML file linked below; but I expect that the Wiki page will change a lot even after the congress, so (as is true for my previous hack) I recommend that you get the script as well.
If you liked this idea take a look at my recently launched website mailfeed.org.
Download
Just before I left my house over the holidays I wanted to print out the schedule for 22C3, and found that I couldn't -- no matter which browser, OS and method I chose, the schedule table was unreadable.
A couple of hours later I sat in a train and had some time to spare, so I hacked together a Ruby script that parses the iCal version of the schedule for 22C3 and creates an HTML page with a clean, readable timetable that you can also print ;)
You can get the script below, and a version of the generated HTML schedule plus style sheet. Note that that one will be out of date at some point (the schedule is updated frequently), so you better get the script too.
See also: Schedule for 22C3 is Now Online; Some Recommendations
Download
I just had a couple of wonderful days of being busy deploying a new site, MailFeed.org. The site is a public service derived from the mailfeed.rb script posted earlier: you send email to an address at mailfeed.org, and it shows up in a public feed. If you don't know it yet have a look at the site, and then come back.
Originally the idea for this arose of a nuisance a friend wanted to get rid of: that there still are people sending out email newsletters instead of writing feeds. But during the last couple of days I found that there are a variety of uses for email-to-RSS gateways beyond that; in effect it could be seen as a generic method of public communication. Multiple authors can easily write to the same feed, and it's as simple to participate in the communication as it is to subscribe.
Before leaving for the holidays (and then attending 22C3) I wanted to briefly sum up the experience, and so I did -- unfortunately this post got a bit longer than usual, but I think it's worth spending the time on it, as we'll touch upon a variety of topics that are related in one way or another, plus there are pictures.
In this text I'll look back at how MailFeed.org got started and then gained some initial public attention, give you a feeling for why I think this method of communication bears both interesting possibilities for public communication and at the same time the tools to undermine itself, and finish with a personal conclusion. And Ruby will be mentioned at least once, I promise ;)
Full entry
Query By Example by Meredith Patterson was one of this year's Google Summer of Code projects, and of all the projects I've looked at it seems the most exciting. Originally I wanted to wait for some more information about the project before writing about it, but as there weren't any news save some quiet early releases, and as I really need to clear my backlog of topics, I decided to have an early look.
Query By Example sets out to get rid of a current limitation of relational databases: the lack of support for fuzzy searches. Here's the short project description:
Query By Example enables intuitive, qualitative queries in PostgreSQL 8.0 and later -- provide a few sample data points, and let the database find similar rows for you.
I should disclaim that I'm not a specialist for database theory, but as an application developer I've had more than one situation where I ended up loading data sets in order to do a computation to decide which data sets to actually load, and Meredith's approach to remove this detour sounds interesting.
Read on for reasons why this is an important project, a detailed overview and a first peek at the SQL syntax.
Full entry
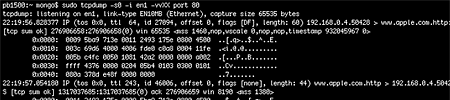
I just updated to 10.4.3, and after the first reboot Little Snitch reported a network request by Dock.app to apple.com -- something which had never happened before. The first time I let it slip, but the second request came when I opened Dashboard for the first time, and this time I started tcpdump before granting access.
Among the expected traffic (updating the weather forecast) was a rather unusual request:
22:19:57.059318 IP (tos 0x0, ttl 64, id 27097, offset 0, flags
[DF], length: 147) 192.168.0.4.50428 > www.apple.com.http: P
[tcp sum ok] 1:108(107) ack 1 win 65535
0x0000: ..[.q>..$..^..E.
0x0010: ..i.@.@.........
0x0020: .[...P..B.N.fvP.
0x0030: ...\..GET./widge
0x0040: ts/widget.info.H
0x0050: TTP/1.1..User-Ag
0x0060: ent:.CFNetwork/1
0x0070: 0.4.3..Connectio
0x0080: n:.close..Host:.
0x0090: www.apple.com...
0x00a0: .
...i.e., an HTTP request for http://www.apple.com/widgets/widget.info, with a user agent of CFNetwork/10.4.3 (CFNetwork is Apple's new networking API introduced with OS X 10.4). The requested plain-text document is as succinct as it is weird:
bert
...and that, as far as I can see, was the full conversation. (I've omitted the reply's HTTP headers as they contain nothing unusual.)
This conversation contains no identifying information, no serial numbers or unique identifiers apart from my IP address, so I'm not really worried about my privacy. And as a Mac user you quickly get accustomed to applications phoning home. But still, usually this happens to check for application updates, so this seemingly senseless request is a bit unordinary, even more so coming from an Apple application.
I'm not really clear about what this means -- at the very least Apple at some point in the near past chose to be notified of certain user actions; maybe they simply want to monitor how often their Dashboard service is used, and in which countries.
But as long as I have no immediate benefit from this transaction I'd like to have a choice to disable these requests, so I started searching for a preference to turn them off -- but there seems to be no plist file that contains the requested URL string, and the Dashboard application doesn't contain it either, nor do the two widgets I use (Apple's weather widget and Widget Machine's Flip Clock). In the end I found the string hard coded in the Dock.app binary:
/System/Library/CoreServices/Dock.app/Contents/MacOS $ strings Dock | grep widget.info
http://www.apple.com/widgets/widget.info
There seems to be little information on this on the web -- a Google search leads to a short discussion in the MacMod forum which more or less documents exactly the same, and at least shows that other people have found this on their systems as well (notably also by having Little Snitch running in the background). And that's about it.
I'd like to document the circumstances under which this kind of traffic occurs, so contact me or write a comment if you find additional information -- e.g. it would be interesting to know if this has been introduced with 10.4.3, so if you haven't updated yet you could check if your Dock binary also contains the same URL.
(By the way, other strings you can find in the Dock binary: "Bunny Rabbit", and "Dashboard: delete widget thread could not create timer. You are hosed".)
FeedTools is an amazingly complete Ruby library by Bob Aman for accessing, parsing and generating feeds from within Ruby. While it is designed to work well with Rails applications, you can just as easily use it in your Ruby scripts:
feed = FeedTools::Feed.open('http://dekstop.de/weblog/index.xml')
puts feed.title
feed.items.each { |item|
puts item.title
puts item.link
}
Requesting a feed every time you run your script is fine as long as you only parse your own feeds, but you should be a bit more polite as soon as you start requesting someone else's feed. Over time feeds can cost site owners a lot of bandwidth, so keep that in mind when you start developing your own feed reader. A proper aggregator keeps a local cache of all feeds and only downloads feeds when they have actually changed, not every time the application is run.
FeedTools has excellent support for keeping and managing such a local cache, it's just not documented very well. So in order to address that I'll show you how I've been caching feed requests with FeedTools 0.2.17, and as you'll see it's quite simple as long as you are aware of some caveats.
Read on for a detailed description and some sample code.
Full entry
I've written a Ruby script that extracts keywords from a MovableType-exported plaintext database, and while doing so wanted to include the Rails Inflector so that the script could merge singular and plural versions of the same word. It wasn't that obvious to me how to include the Inflector in Ruby scripts outside of Rails, and I searched for a while until I found the proper usage; so I'll document it here to save other Ruby newbies some time.
In the end it boiled down to finding the proper require statements -- I'm not sure if this is the best way though, so any comments are appreciated. Here's how you do it:
#!/usr/bin/ruby
require 'rubygems'
require 'active_support/inflector'
puts Inflector.singularize('inflections')
Read on for an explanation of why this isn't as obvious as it may seem.
Full entry