I just got a mail from Patrick, a friend of mine whose job mainly consists of working on very cool interfaces all day long, and who some time last year started circuit bending with his friend Dennis. They took apart cheap children's keyboards, soldered random bits and pieces onto their circuitry, and then presented their setup at last week's dorkbot at c-base here in Kreuzberg. Sadly I missed the performance, but there's a video ("circuit benders from hell", 30 MB Quicktime -- I don't think he minds that I share the link).
Look ma, they're using my mixer! (An amazing piece of equipment btw, and very cheap.)
I've been submitting feature requests and bug reports to the NetNewsWire forum -- Brent Simmons seems pretty responsive. I'm looking forward to an application update, it's been months since 2.01 was released, and I'm wondering what Brent's working on (probably mainly NewsGator integration, which at the moment is of little use to me.) The more I'm using the application the more I'm finding its limitations -- it's still the best aggregator for the Mac (though Vienna is getting closer and closer), but sometimes I'm a bit envious of the Windows world where FeedDemon is making great strides lately. I'm still thinking about new ways to improve aggregator interfaces, so expect updates to my earlier article about that topic.
A propos aggregators: I need a better workflow to read feeds. Too many high-traffic feeds amount to 10,000 unread articles in the last couple of weeks. I'm on and off developing a web-based aggregator to manage a specific subsection of my subscriptions, but that'll take a while, and I already found that the application I'm envisioning will be too resource-hungry for a shared host, yet I don't have the money for a dedicated server -- I'll finally have to look into localhosting (i.e., having a server at home that is accessible from the outside).
And speaking of resource-hungry applications in a shared hosting environment: I took down my MailFeed service for an indefinite time, see mailfeed.org for details. (I have some alternate ideas involving procmail scripts, but that has to wait.)
Edit: The bit about the first ever R470K live circuit bending performance has moved to an article of its own.
I make a lot of little notes in text files that never develop into a full article and eventually get deleted. So to change that, and to maybe even increase the post frequency a bit, I'll start publishing smaller comments. Have no idea yet which way suits me best though; first approach: assemble several semi-connected commentaries to get to article length.
TextMate 2.0, which I guess won't be released within the next six months, will be a free update for registered users of TextMate 1.x -- a bold financial decision for the developer Allan Odgaard, but great for his users. I guess most of his users are twens and/or students, so it's a really friendly move. To give a vague point of reference: TextMate serial numbers are given out sequencially; I registered in late December 2005 and my serial number is around 4,500.
On a slightly different note, I was testing Measure Map on this site for a couple of weeks, but after the first acquisition announcements a couple of hours ago decided to quit. The main reason I initially chose Measure Map over Google Analytics was that I don't want to feed the data monster more than I need to; well that turned out great. (Hint for lazy readers: Google just bought Measure Map.) Javascript-based stats suck anyway, so no harm done.
...and I agree with Alex Payne: "Loveless" is an amazing album.
I just started to write an aggregator in Ruby which will form the basis of a number of web applications, and a couple of minutes into the project I'm already excited about the expressiveness of Ruby and its standard library. So much so that I had to share the results of my first five minutes of coding.
I decided that the aggregator I'm writing will take its feed URLs from an OPML document.
A nice property of OPML is that it allows you to group feeds into a hierarchy of named elements, so that you can e.g. group some feeds in a "blogs" category, some other feeds in a "news" category, and so on. You could even have subgroups, so that e.g. your "news" category has subcategories "politics", "weather", "tech", etc.
So I thought a bit about how you can parse the OPML in a way that extracts feed URLs and still preserves this notion of hierarchical "categories" -- and it turns out it's remarkably simple, and it did indeed only take a couple of minutes to implement, most of which was spent reading up on API calls.
Here's the complete function:
# parse_opml (opml_node, parent_names=[])
#
# takes an REXML::Element that has OPML outline nodes as children,
# parses its subtree recursively and returns a hash:
# { feed_url => [parent_name_1, parent_name_2, ...] }
#
def parse_opml(opml_node, parent_names=[])
feeds = {}
opml_node.elements.each('outline') do |el|
if (el.elements.size != 0)
feeds.merge!(parse_opml(el, parent_names + [el.attributes['text']]))
end
if (el.attributes['xmlUrl'])
feeds[el.attributes['xmlUrl']] = parent_names
end
end
return feeds
end
And here's how you call it:
require 'rexml/Document'
opml = REXML::Document.new(File.read('my_feeds.opml'))
feeds = parse_opml(opml.elements['opml/body'])
To make it clear what I'm trying to do I'll show you a simple example. If this is the content of my_feeds.opml:
<opml version="1.1">
<body>
<outline xmlUrl="http://example1.com/feed" />
<outline text="blogs">
<outline xmlUrl="http://example2.com/feed" />
<outline text="dev">
<outline xmlUrl="http://example3.com/feed" />
</outline>
</outline>
</body>
</opml>
...then the hash returned from parse_opml will look like this:
{
"http://example1.com/feed" => [],
"http://example2.com/feed" => ["blogs"],
"http://example3.com/feed" => ["blogs", "dev"]
}
And I'm still amazed. Eat this, PHP ;)
Related Articles
For the last couple of years I've been toying with ideas on how to cut back on my expenses, and one of the top items is the plan to cancel magazine subscriptions. They don't actually cost that much, but I've been getting better information elsewhere, and usually quicker; to me the print media is on the verge of becoming irrelevant.
But every couple of months I stumble upon an article in the printed press that I didn't catch via other channels, and that manages to refresh my interest in the old media. Today was one of those days: while flipping through Saturday's edition of c't magazine (Germany's best IT news source in print) I got to know about a new venture IBM and some other parties announced back in January: the Peer to Patent Project, an attempt to establish community peer review for patents.
Here's how they describe themselves:
The patent system needs our help. The United States Patent Office is actively seeking ways to bring greater expertise to bear on the review of patent applications and ensure that only worthwhile inventions receive the patent monopoly. Currently, underpaid and overwhelmed examiners struggle under the backlog of applications. Under pressure to expedite review, patents for unmerited inventions are approved. [...]
The Community Patent Project aims to design and pilot an online system for peer review of patents. The Community Patent system will support a network of experts to advise the Patent Office on prior art as well as to assist with patentability determinations. By using social software, such as social reputation, collaborative filtering and information visualization tools, we can apply the wisdom of the crowd or, more accurately the wisdom of the experts to complex social and scientific problems. This could make it easier to protect the inventors investment while safeguarding the marketplace of ideas.
To improve the sorry state of the US patent system IBM proposes an approach comprised of three elements: first an open, peer-reviewed patent application process (which is where the quote above comes from); second a process to evaluate and establish prior art cases in open source software; and third a process to establish a "patent quality index", which is to be a numeric evaluation of the quality of patents and patent applications. (The last part sounds a little esoteric to me, and gives us a hint at how artificial a construct intellectual property law actually is. How can you seriously consider to compare two unrelated ideas in terms of their "quality", whatever that is?)
To me the most interesting part is the first proposal; it was about time that the USPTO introduced peer review to the patent system. I wrote about a similar idea back in September of 2005, which I consider to be fairly late for such an obvious concept (see "RFC: Patent Approval Process via Communities"). And yet I'm surprised how quickly these established mainstream organizations caught up with the state of things -- this sounds like something that might actually happen.
Of course there are a number of practical obstacles. How do you reconcile peer review with the (understandable) desire to keep patent applications private? How do you handle conflicts of interest, where the guy best suited to evaluate your patent application might be your direct competitor? How do you make such a system tamper-proof and "spam"-resistant? Who do you include in the discussion? How can you motivate enough individuals from both a scientific and an industry background to partake in the process without having to actually pay them? Can private citizens participate, too?
Establishing such a scheme is really hard, and besides changes in the way government does its job it requires support from major industry parties. It's probably not surprising that this turned out to be IBM's part, considering their recent foray into more open development practices. Yeah it's great that the OSDL is involved too (apparently mainly for the second element of the proposal, finding prior art in open source software), but it's neither a large step for them nor do they endanger their livelihood as much by "risking" a more open process; it's the established industry that actually needs to change its modus operandi.
So it's going to be very interesting to watch this evolve. It'll take some time to review the existing documentation (let me know if you find a good blog/overview about this), but I suggest you subscribe to the Peer to Patent Project feed, and start discussing these ideas with some managers and IP lawyers in your area of influence to get the ball rolling. I know I will.
And if you actually live in the US (which I don't) you'll have a chance to see the project evolve, and to have an influence on its direction: see the Workshops and Events page for details. ("Hosted by preeminent faculty at leading universities and convened by Professor Beth Noveck, Director, Democracy Design Workshop, New York Law School, the Workshops will meet around the country during Spring 2006.")
Related Links
A couple of days ago Jon Udell complained about the alledged "customer lock-in" in Apple's iTunes:
...although the podcast's feed URL is discoverable by way of the Show Description contextual menu option, the ensuing dialog box does not permit the displayed URL to be copied. That's why I had to manually transcribe the URLs...
Via 0xDECAFBAD's daily del.icio.us links we're notified of an article on BlogicBlog, "The techie way of liberating the podcast URL from iTunes", where the unnamed author suggests to use a network sniffer like Ethereal to watch outgoing traffic while you refresh the respective feed in iTunes -- but as the author admits its far from user-friendly (and commandline junkies will be quicker with tcpdump or tcpflow anyway).
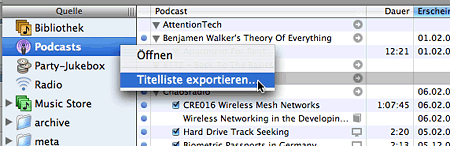
But so far nobody has pointed towards the obvious: iTunes already has OPML export. Right-click on the "podcasts" source item, select "export" from the popup menu, select your desired output format, and there you go. Viewable with any text editor.
Yeah it's a pity that not every text field in iTunes is selectable, but to suggest Apple is locking in their customers is a bit strongly worded. To me it looks more like an oversight.
This must be the most entertaining short I've seen in months. A couple of very geeky Brits, introduced by a Swede, show you how they are using Erlang as part of their PABX (or PBX, as the youngsters are calling it these days), and demonstrate the usefulness of realtime, declarative, symbolic programming. Is it industrial advertising? Or educational? Or is it just an awesome piece of academic retro futurism? Is it subversive comedy, dripping with pop cultural references and contemporary irony, or quite to the contrary simply an antiquated piece of another time?
You decide.
It's much more efficient!
 |
"Declarative programming languages have several advantages over traditional languages. For example, programs in such languages are considerably shorter than the equivalent programs in imperative languages." |
 |
"Here, for example, is a program in C." (Scrolls over 250 lines of C code.) |
 |
"And here is the equivalent program in Erlang." (Audience goes nuts.) |
Watch us communicate!
 |
Hello, Robert. Hello, Mike. Hello, Joe. Hello, Robert. Hello, Mike. Hello, Joe. Hello, Robert. |
Links
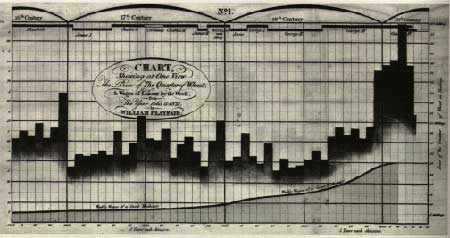
I just got a copy of Edward Tufte's 'The Visual Display of Quantitative Information', and while I only skimmed over a few passages I found its historical examples of data visualization intriguing. A little searching then brought up "Milestones in the History of Thematic Cartography, Statistical Graphics, and Data Visualization", which is an interesting gallery and timeline of the development of the modern info-graph. While many examples shown there do indeed focus on mapping applications, the cornerstones of data visualization are all there, and the site shares many of the examples Tufte also uses in his book.
This week I presented a more detailed summary of this topic to a couple of friends, and you can see the text version of this at http://mardoen.textdriven.com/dienstag/2006-01-17/dataviz/, including a short list of contemporary examples for computerized visualizations, both interactive and static. The following article is an excerpt of this presentation.
Read on for more.
Full entry
There currently are quite a number of very happy reactions over the announcement that Telestream's product Flip4Mac WMV is now available for free -- Flip4Mac WMV is a collection of "Windows Media® Components for QuickTime" that allows you to play certain Windows Media formats from within Quicktime, among them apparently some older formats that Microsoft's Media Player 9 for OS X can't play (I'm not actually sure about that, but this seems to be a reason why people install it -- that and the fact that MS has just discontinued their own Media Player.)
It's curious that there is a download link on the Microsoft website which clearly omits any mention of Telestream; in my opinion this gives a credibility to the product that it doesn't necessarily deserve, and which leads to the mistaken notion that it is a Microsoft product, which it is not. Flip4Mac is made by Telestream, not by Microsoft.
Frankly I'm a little annoyed by how much of the reactions seem to boil down to an unreflected "Oooh, shiny!" -- granted, it looks like a well-designed product, but by using it you have to accept a list of strange conditions.
Read on for some irritating excerpts of the Flip4Mac EULA, and a request for clarification.
Full entry