Last weekend I was at the music hack day in London, organised by Dave Haynes and James Darling: a two-day event where software developers met up and wrote music-related software (or built hardware.) Instruments, a distributed content resolver, various SoundCloud tools, etc.
Although the event attracted lots of interesting people from all over the planet (well, Europe) I ended up coding most of the weekend instead of talking. (On that note, I'm still amazed by the amount of time coding requires, even after you learned how to channel your ambitions more efficiently. Software development is still a painful process.)
I built a small single-page site: Music Feeds, a river-of-news aggregator of music-related RSS feeds, where you can filter the incoming posts via Last.fm user attention profiles. For example: my own profile at the moment uncovers a lot of dubstep-related posts, because that is what I've been listening to. A surprising amount of the Last.fm profiles I tested with evoked Michael Jackson-related posts. Etc.
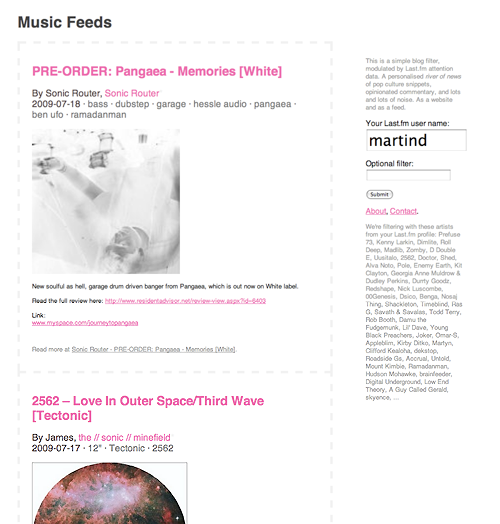 |
| Music Feeds: a simple blog filter, modulated by Last.fm attention data. |
Music feeds provides you with multiple filters, and you can mix them freely: A Last.fm attention profile filter that uncovers posts referencing the names of the user's most listened-to artists. The ability to browse by category/topic, as provided by the blog post's author. A filter by keyword search (which the former two are based on.)
Some examples:
- Posts for Last.fm user 'martind'
- Additionally filtered with a keyword match for 'dubstep'
- UK Funky podcasts, Skweee podcasts (check the enclosure section at the end of each post, or subscribe to the feed)
- Just reviews (or more specifically, only posts that have a category of "review")
I see it as a basic toolbox for writing simple notification mechanisms; a way to combine behavioural data and text search into a news filtering mechanism that is hopefully both sufficiently reactive to a person's changes in interest, but also specific enough to pick out distinct elements from a noisy influx of posts.
Thanks to music feeds I already found out that FWD>> is now offering mp3 downloads of their nights, that there is a new Hotflush podcast, and that FACT generally keeps releasing great mixes. Finding out about this became effortless. I also learned that Lisa Blanning published a great interview with Madlib in the Wire. And a random "Shoreditch" search uncovered that my colleague Helen is releasing a PENS debut album.
So what is this.
It is definitely not an edited medium. There is no flow, no binding voice, and the nature of what you see varies wildly with your search query and the time of search.
It's not a recommendation mechanism. There is no reasoning about user taste models, no predictive algorithm behind what is shown. What's shown is simply what could pass the filters.
It's also not an archive. It has neither pagination, nor permalinks, not even a URL structure. This is deliberate and will probably not change. (Partially of born out of a consideration for "intellectual property" legislation, and partly because this shouldn't turn into a republisher.) At the core of it there is just a stream of incoming posts and a search query that acts as a filter. It's sort of a routing/messaging system; or at least it is more this than it is a corpus of documents that you access like a library.
I see it as a useful notification mechanism that you can make use of on the side. It's a supplementary medium. A substitute for randomly turning on the TV. In its best moments it could be a substitute for actively pursuing news, but I wouldn't expect that to happen a lot.
In the end it's just a text search.
On the other hand I would still consider this a social filter, because people now become shorthands for quite complex search queries. Your search fu becomes stronger by getting to know other Last.fm users, or at least their profiles; this allows you to pick your "viewpoint." You can learn about new music, or achieve a specific mixture, by browsing other people's streams. So like with Pool Radio this is also about people as mediators.
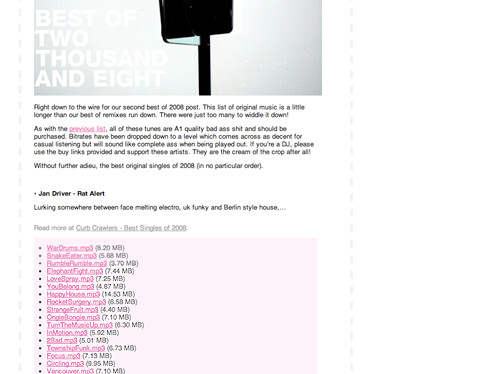 |
| Music Feeds displays feed enclosures, and can be used as a simple podcast generator. Just subscribe to the feed of a search result page. |
Limitations
Thor's stream, despite the interesting mixture of its topics, also demonstrated some systemic flaws. When I first started browsing it there was always a little too much Jay-Z in his stream. And he also always had a post by the same annoying real-estate feed right at the top, just because that seemed to be a really active feed, i.e. always had new stuff. (That feed has now been removed.)
These apparent flaws are also a little interesting. Especially since the effect of this social filter may change over time. A lot of recent searches I made brought up Michael Jackson posts; both because Last.fm users whose accounts I was testing with had listened to him a lot, but also because people wrote more about him. This will soon go away and then be replaced with something else.
Sometimes however you only get "noise", too much stuff that matched random keywords regardless of actual theme. A good indicator that a.) the system still needs more feeds for loads of ill-represented musical subcultures, and b.) you do need to listen to a certain type of music to make this work.
It obviously works best with music that people write about at this time, because it's current or topical.
Yet if your own listening habits are towards the non-topical this search model could still be interesting as a notification mechanism -- e.g. to keep looking for unexpected album releases, just in case.
But that requires that the artist names in one's Last.fm profile are unique enough so they don't cause too many false positives. My own Last.fm filter keeps letting posts through that randomly match the name of the grime artist "Doctor", without actually being about the artist.
On the Source Data
It helps a lot that this is based on a fairly controlled data set -- these are mostly hand-picked feeds, even in cases where I didn't do the picking myself. Initially I thought about implementing a crawler, but at this point that is probably counter-productive. I only want good feeds. I don't want to have to waste time on implementing ranking algorithms.
But obviously I don't want to hand-pick them all myself. So instead I'm concentrating on finding good mediators for feed URLs:
- My own private subscriptions, just because you have to start somewhere.
- The Hypem blog list (thx!), one of the best sources by far, but with a skew towards mp3 blogs (which means they don't have any other good music blogs.)
- The Technorati Music Blogs directory.
- To a smaller extent: manually traversing music blog link rolls (As a result there are a whole bunch of London-based blogs in there now.)
- And then Thor sent me his Google Reader OPML file -- ca. 400 great & original music feeds I didn't have! Goldmine!
Finally, the inverse: I spent a fair amount of time on pruning feeds that didn't quite fit. Gossip blogs, lifestyle wank, real estate "reporting" (esp. the vicarious kind), news, ... there's a lot of adjacent stuff that sort of happens in a similar context, and it's OK to have up to a degree. But mostly it's just a distraction.
Next up, maybe: getting artist homepages from MusicBrainz and determining which ones have a feed. Still unsure about that one. I'm neither interested in PR blogs nor in the touring minutiae of random rock bands, so this might just be a pandora's box.
(Do you read a lot of music blogs? Or know other good music blog link lists? Let me know/send me your OPML file!)
Briefly on the Technology
I built a feed aggregator a couple of months ago in Python, with Mark Pilgrim's feedparser, PostgreSQL, etc. At the moment it aggregates ca. 3k blogs, the size of the archive just surpassed 700k posts. Music Feeds is based on this archive.
It's using Solr for search. Artist name search is peculiar because stemming rules don't really apply; which acts in our favour since it means we don't have to worry about language models. Additionally we benefit from Last.fm's scrobble metadata corrections, i.e. the attention data we get is fairly clean, so a simple text search against our corpus works really well.
Music Feeds has a very simple PHP UI. I love removing features.
This was also a chance to try VirtualBox and run a Debian dev server on OS X. Virtualisation is great. VirtualBox is nice & pretty, but at times it also becomes apparent that writing a solid VM is an artform that takes years of practise.
Music Feeds and the architecture behind it was partially written in Zürich, San Francisco, and Sardinia. Mostly in London though. (This year I get to travel a lot.)
Comments
Comments are closed. You can contact me instead.