 |
Made a thing in an "introduction to programming" class where non-engineers learned to write code. I might actually stick around, was fun to spend time on a random sketch while everyone else learned about variables. |
P5 Sketch: Sprites and Feedback Texture Rendering
Martin Dittus · 2011-10-03 · code · write a comment
Heatmap Calendars of Last.fm Scrobbles
Martin Dittus · 2011-09-10 · code, data mining, konsum, muzak, pop culture, tools · 4 comments
After five amazing years at Last.fm I decided to hand in my notice a few months ago, my last day was at the end of August. As a parting gift and sign of appreciation of the many things Last.fm has given me I produced a series of data visualisations of the scrobbles of all Last.fm staff, alumni, and community moderators I could find, and published it last week.
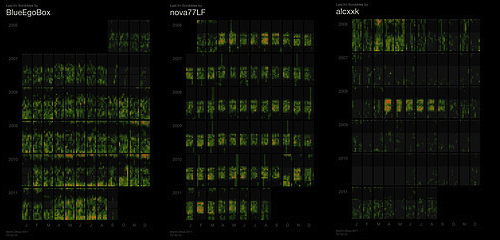
In total the series encompasses 8.7 million scrobbles across ~180 graphs. The visualisation is a structured heatmap that is designed to reveal periodicities: years, months, day of week, hour of day.
Storytelling With Scrobbles
 |
Excerpt of underpang's graph, showing the years 2005-2007. |
It is often most interesting to read either your own graph or that of someone you know well.
David Singleton published a blog post about his own graph, in which he writes:
Despite the depth of information its stunningly readable and rather interesting. You can pick out real patterns quite easily [...]
From my graph I was able to spot these behaviours:
- Mid-2005 to 2006 - Finished Uni, got a job and spent the first 6+ months commuting with iPod after moving to London was still missing a laptop for a long time.
- Late 2007 - An increase in evening listening, a sign of joining the Last.fm team and getting stuck in to startup culture of late nights.
- Early 2008 - Evening listening, but with more separation from daytime listening. I suspect this was nights spent playing albums with my flatmate Ben Ward.
- 2009 - Less evening music, which I think stems from different flat mates, a different flat and starting an (unscrobbled) vinyl collection.
- February 2010 - A quiet month for scrobbling, most of which on holiday in New York, little time for digital music.
If you don't know the person portrayed you will find it hard to recognise the stories captured by this visualisation. While you may see changes in behaviour they will be meaningless without the necessary context.
To make up for this I asked a few people to share what they can read from their own graphs, and published their notes in the form of an annotated gallery of Last.fm Heatmap Calendars. (David Whittle tells me this is a variant of a Diary Study.)
|
There is an amazing diversity of patters across the different graphs. Every person's graph has a truly characteristic shape. These are the heatmap calendars for BlueEgoBox, nova77LF, and alcxxk. |
Future Work
In principle this visualisation is applicable to all kinds of event streams, with a few limitations. It requires a fair number of events: graphs based on less than tens of thousands scrobbles often weren't detailed enough.
It works best for events that happen at least several times a day over a duration of years, and where event occurrence is at least moderately structured; entirely random events will just produce a noisy chart.
It could feasibly be applied to: IRC/IM/email communication, phone call logs, credit card transactions, WikiLeaks cables (by embassy or topic), software version control histories, transport data (e.g. produced by TfL's Oyster card or bike rental schemes), tweets, blog posts, transactions in markets and auction systems, and many more.
Links
- Annotated Gallery of Last.fm Heatmap Calendars
- The full Flickr set: Last.fm Heatmap Calendars
- Infosthetics post: Revealing the Periodic Listening Habits of last.fm Users
Noise Making Machines
Martin Dittus · 2011-04-24 · diy, electronics, muzak

Young Hackspace
Martin Dittus · 2011-04-24 · diy, events, hackerspaces · write a comment

In early 2011 we started the Young Hackspace: a monthly event where we invite groups of young children or teenagers to the London Hackspace and show them how to make things. It started with a chance encounter (I was giving a Hackspace tour to two interested parents) and quickly grew into an amazing regular encounter between hackers and kids...
We started with a laser cutter workshop for eight year olds, combined with demonstrations of lasers in action; then a wood working and print making workshop; soon we'll have a "making electronic beats" workshop, probably in combination with a few "physics of sound" demonstrations; and there's no lack of ideas for future workshops. Proposed so far: a monorail building workshop, a robotics workshop, ...
None of this would have been possible without the skill and seemingly limitless enthusiasm of London Hackspace contributors. Tom Wyatt, Will Pearson, Daniel Hertz, Kirsten Skillen, Billy Smith, Sam Kelly, Anthony Bowyer-Lowe, ... more to come soon!
Links
- young-hackspace.org.uk
- Follow @younghackspace for updates.

Music Feeds -- Pop Culture Snippets, Opinionated Commentary, and Lots and Lots of Noise
Martin Dittus · 2009-07-18 · data mining, konsum, pop culture, recommendation engines, tools, web services · write a comment
Last weekend I was at the music hack day in London, organised by Dave Haynes and James Darling: a two-day event where software developers met up and wrote music-related software (or built hardware.) Instruments, a distributed content resolver, various SoundCloud tools, etc.
Although the event attracted lots of interesting people from all over the planet (well, Europe) I ended up coding most of the weekend instead of talking. (On that note, I'm still amazed by the amount of time coding requires, even after you learned how to channel your ambitions more efficiently. Software development is still a painful process.)
I built a small single-page site: Music Feeds, a river-of-news aggregator of music-related RSS feeds, where you can filter the incoming posts via Last.fm user attention profiles. For example: my own profile at the moment uncovers a lot of dubstep-related posts, because that is what I've been listening to. A surprising amount of the Last.fm profiles I tested with evoked Michael Jackson-related posts. Etc.
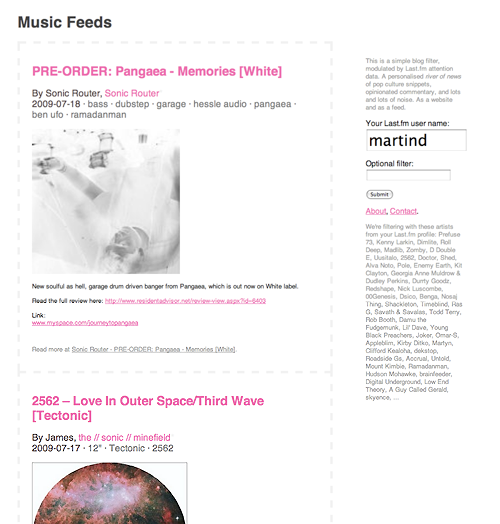 |
| Music Feeds: a simple blog filter, modulated by Last.fm attention data. |
Music feeds provides you with multiple filters, and you can mix them freely: A Last.fm attention profile filter that uncovers posts referencing the names of the user's most listened-to artists. The ability to browse by category/topic, as provided by the blog post's author. A filter by keyword search (which the former two are based on.)
Some examples:
- Posts for Last.fm user 'martind'
- Additionally filtered with a keyword match for 'dubstep'
- UK Funky podcasts, Skweee podcasts (check the enclosure section at the end of each post, or subscribe to the feed)
- Just reviews (or more specifically, only posts that have a category of "review")
I see it as a basic toolbox for writing simple notification mechanisms; a way to combine behavioural data and text search into a news filtering mechanism that is hopefully both sufficiently reactive to a person's changes in interest, but also specific enough to pick out distinct elements from a noisy influx of posts.
Thanks to music feeds I already found out that FWD>> is now offering mp3 downloads of their nights, that there is a new Hotflush podcast, and that FACT generally keeps releasing great mixes. Finding out about this became effortless. I also learned that Lisa Blanning published a great interview with Madlib in the Wire. And a random "Shoreditch" search uncovered that my colleague Helen is releasing a PENS debut album.
So what is this.
It is definitely not an edited medium. There is no flow, no binding voice, and the nature of what you see varies wildly with your search query and the time of search.
It's not a recommendation mechanism. There is no reasoning about user taste models, no predictive algorithm behind what is shown. What's shown is simply what could pass the filters.
It's also not an archive. It has neither pagination, nor permalinks, not even a URL structure. This is deliberate and will probably not change. (Partially of born out of a consideration for "intellectual property" legislation, and partly because this shouldn't turn into a republisher.) At the core of it there is just a stream of incoming posts and a search query that acts as a filter. It's sort of a routing/messaging system; or at least it is more this than it is a corpus of documents that you access like a library.
I see it as a useful notification mechanism that you can make use of on the side. It's a supplementary medium. A substitute for randomly turning on the TV. In its best moments it could be a substitute for actively pursuing news, but I wouldn't expect that to happen a lot.
In the end it's just a text search.
On the other hand I would still consider this a social filter, because people now become shorthands for quite complex search queries. Your search fu becomes stronger by getting to know other Last.fm users, or at least their profiles; this allows you to pick your "viewpoint." You can learn about new music, or achieve a specific mixture, by browsing other people's streams. So like with Pool Radio this is also about people as mediators.
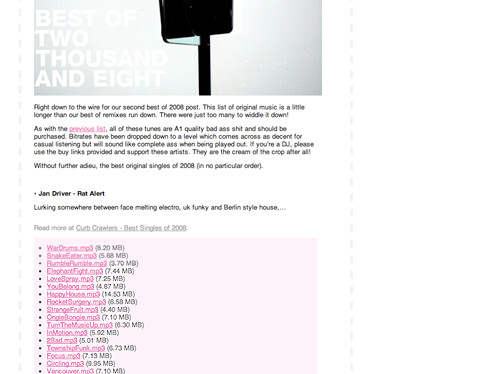 |
| Music Feeds displays feed enclosures, and can be used as a simple podcast generator. Just subscribe to the feed of a search result page. |
Limitations
Thor's stream, despite the interesting mixture of its topics, also demonstrated some systemic flaws. When I first started browsing it there was always a little too much Jay-Z in his stream. And he also always had a post by the same annoying real-estate feed right at the top, just because that seemed to be a really active feed, i.e. always had new stuff. (That feed has now been removed.)
These apparent flaws are also a little interesting. Especially since the effect of this social filter may change over time. A lot of recent searches I made brought up Michael Jackson posts; both because Last.fm users whose accounts I was testing with had listened to him a lot, but also because people wrote more about him. This will soon go away and then be replaced with something else.
Sometimes however you only get "noise", too much stuff that matched random keywords regardless of actual theme. A good indicator that a.) the system still needs more feeds for loads of ill-represented musical subcultures, and b.) you do need to listen to a certain type of music to make this work.
It obviously works best with music that people write about at this time, because it's current or topical.
Yet if your own listening habits are towards the non-topical this search model could still be interesting as a notification mechanism -- e.g. to keep looking for unexpected album releases, just in case.
But that requires that the artist names in one's Last.fm profile are unique enough so they don't cause too many false positives. My own Last.fm filter keeps letting posts through that randomly match the name of the grime artist "Doctor", without actually being about the artist.
On the Source Data
It helps a lot that this is based on a fairly controlled data set -- these are mostly hand-picked feeds, even in cases where I didn't do the picking myself. Initially I thought about implementing a crawler, but at this point that is probably counter-productive. I only want good feeds. I don't want to have to waste time on implementing ranking algorithms.
But obviously I don't want to hand-pick them all myself. So instead I'm concentrating on finding good mediators for feed URLs:
- My own private subscriptions, just because you have to start somewhere.
- The Hypem blog list (thx!), one of the best sources by far, but with a skew towards mp3 blogs (which means they don't have any other good music blogs.)
- The Technorati Music Blogs directory.
- To a smaller extent: manually traversing music blog link rolls (As a result there are a whole bunch of London-based blogs in there now.)
- And then Thor sent me his Google Reader OPML file -- ca. 400 great & original music feeds I didn't have! Goldmine!
Finally, the inverse: I spent a fair amount of time on pruning feeds that didn't quite fit. Gossip blogs, lifestyle wank, real estate "reporting" (esp. the vicarious kind), news, ... there's a lot of adjacent stuff that sort of happens in a similar context, and it's OK to have up to a degree. But mostly it's just a distraction.
Next up, maybe: getting artist homepages from MusicBrainz and determining which ones have a feed. Still unsure about that one. I'm neither interested in PR blogs nor in the touring minutiae of random rock bands, so this might just be a pandora's box.
(Do you read a lot of music blogs? Or know other good music blog link lists? Let me know/send me your OPML file!)
Briefly on the Technology
I built a feed aggregator a couple of months ago in Python, with Mark Pilgrim's feedparser, PostgreSQL, etc. At the moment it aggregates ca. 3k blogs, the size of the archive just surpassed 700k posts. Music Feeds is based on this archive.
It's using Solr for search. Artist name search is peculiar because stemming rules don't really apply; which acts in our favour since it means we don't have to worry about language models. Additionally we benefit from Last.fm's scrobble metadata corrections, i.e. the attention data we get is fairly clean, so a simple text search against our corpus works really well.
Music Feeds has a very simple PHP UI. I love removing features.
This was also a chance to try VirtualBox and run a Debian dev server on OS X. Virtualisation is great. VirtualBox is nice & pretty, but at times it also becomes apparent that writing a solid VM is an artform that takes years of practise.
Music Feeds and the architecture behind it was partially written in Zürich, San Francisco, and Sardinia. Mostly in London though. (This year I get to travel a lot.)
Field: Next-Gen IDE for Generative Design
Martin Dittus · 2009-05-16 · tools · write a comment
 |
Mark Downie on the Field-development list:
More seriously, the trick I think with Processing is that it has been a wonderfully successful "stone soup". The IDE and its graphics architecture are left over from a different era and I can't see why it's language modifications are worth maintaining, but the vibrant community and library maker ecosystem is unlike anything else that's happening. But these two things are largely separable. The aim is to be able to connect with the latter while leaving the former behind.
Quite a few people are realizing this for example, lots of people are justifiably excited about a JRuby / Processing mix. But the issue then becomes the lack of genuinely interesting IDEs. Netbeans and Eclipse make excellent hosts for staid, corporate, "large" programming but they aren't a good fit for something exploratory, experimental, time-based and live.
The questions then that somebody embarking on a new digital-art-code-thing are: 1) why a new language? 2) why not integrate into something like Eclipse? 3) and what are you going to do about your libraries?
Processing answers: 1) because html color literals are super important; 2) Eclipse is too hard; 3) we built it and they came.
OpenFrameworks answers: 1) Let's just use the sane subset of C++ and hope it doesn't get too out of control; 2) Let's just use a real IDE; 3) All the powerful libraries are actually in C anyway.
Field answers: 1) Languages are interesting but hard to get right --- let's have Python and a bunch of others; 2) Because Eclipse is too big, too boring and doesn't understand the live coding story at all; 3) Let's hijack Processing libraries where they are useful, and supply our own where they aren't.
Field is now in public beta.
Google News Almost Bankrupts Multinational
Martin Dittus · 2008-09-11 · a new world · write a comment
This is mind-boggling. Think of the possibilities. Bringing down companies with a bit of crowdsourcing? Check.
The Wall Street Journal reports that Google News crawled an obscure reprint of an article from 2002 when United Airlines was on the brink of bankruptcy. United Airlines has since recovered but due to a missing dateline, Google News ran the story as today's news. The story was then picked up by other news aggregators and eventually headlined as a news flash on Bloomberg. This triggered automated trading programs to dump UAL, cratering the stock from $12 to $3 and evaporating 1.14 billion dollars (nearly United's total market cap today) in shareholder wealth. The stock recovered within the day to $10 and is now trading at $9.62, a market cap of $300M less than before Google ran the story.
The article makes clear that Google's news bot only noticed the old story because it has been voted up in popularity on the site of the South Florida Sun-Sentinel newspaper. The original thought was that stock manipulation may have been behind the incident, but this suspicion seems to be fading.
Source: Slashdot, "Automated News Crawling Evaporates $1.14B
Pool Radio: An Aggregator of Mediators
Martin Dittus · 2008-05-10 · code, konsum, pop culture, recommendation engines, tools · write a comment
Over the past extended weekend I created Pool Radio, a tool that provides access to hopefully interesting Last.fm radio stations. See also the announcement in the Subscribers and their tag radio stations group forum, with some great comments by Nectar_Card.
I'm aware that not a lot of people will find this site very useful, but people with an appreciation for the random and obscure can definitely benefit from it. Here are a couple of great user tag stations I've enjoyed over the last week: raw_u's etiopia tag radio (tag page), jirkanne's lllllllllllllll tag radio (tag page), JessiCoplin's scott storch tag radio (tag page), mathman_mr_t's ab-ex minimalism tag radio (tag page), ...
 |
Yeah k, But Why?
I've become blatantly lazy when it comes to finding new music. On top of that I'm interested in a lot of random stuff, across the entire spectrum from popular music to more obscure things, and often the things that catch my interest don't necessarily bear any relation with what I've been listening to in the past.
So while Last.fm recommendations are useful to a lot of people, in most cases I'm not really interested, mainly because they are directly influenced by my past listening profile, and that's not what I'm personally looking for. They're not designed to show you random new stuff, they won't result in anything close to what a knowledgeable mediator can curate. They're a great way to navigate an abundance of music, but they're no replacement for John Peel.
Instead I'm more interested in finding mediators: people or groups who spend a lot of time finding stuff, and then publishing it. Doing what used to be done by music magazines or radio stations, but with contemporary means. Because now music geeks publish their findings online; and arguably the largest source of those is the Last.fm community. We should make use of them!
Unfortunately atm Last.fm itself makes finding those mediators rather hard, we simply don't have a lot of focus on this aspect of the music attention economy. While Last.fm is great for "six degrees of separation"-type social discovery (finding stuff by looking at user profiles, their groups, their friends, etc) we lack more explicit mechanisms that provide exposure to those mediators (users, groups, ...); that allow other users to reward mediators for creating interesting collections. Our tag editors aren't that great (I think everybody inside the company can agree on that.) Also, you can't even bookmark radio stations, or conveniently recommend them.
As a result, often people create their own mechanisms for these processes, which is a testament on the great usefulness of our basic architecture. People start groups that are centered around the fascination of finding and sharing stuff. Here are a couple of great ones:
- Music Advice Center, probably the most active group for good old music discussion geek-outs.
- Thursday Night Party Hat Party, an awesome social sharing experiment across timezones and genres.
- The 1 Percenters, an attempt to shape a "varied and non-mainstream" group radio by requiring its members' profiles to fulfil two simple criteria (not to be confused with the 1% group, who are just elitists.)
- Obscure Music Recommendations, "dedicated to discovering fantastic bands and giving them the appreciation they deserve."
- And of course the aforementioned Subscribers and their tag radio stations.
So for the future I'd love to see more mechanisms that explicitly encourage and channel this kind of behaviour. It's admittedly hard to design those (simple, yet immediately useful) systems, but I think in the end people are the best filters, which is also why imho Last.fm's collaborative filtering creates a much more interesting collection of music bundles than systems purely based on feature extraction.
(Disclaimer: I'm a software developer at Last.fm, but I'm not part of any product development team. I have no influence on these matters, aside from having the benefit of access to people who do.)
Hadoop Summit 2008
Martin Dittus · 2008-03-30 · a new world, conferences, data mining, software · 4 comments
 |
Johan and I were overjoyed: last week Last.fm sent us to the Hadoop Summit 2008 in Santa Clara, California. Under Johan's wings Last.fm became one of the earliest adopters of Doug Cutting's Hadoop, and I'm a frequent user myself.
And we had an excellent time. The conference was great as expected, we had lots of interesting conversations with people from all kinds of backgrounds. Additionally we spent the rest of our trip meeting people from other companies (Facebook, Powerset, and others), discussing technology (we're currently really interested in HBase), the various issues that arise from having to cope with increasingly large data sets, etc.
It was very apparent that we're witnessing the emergence of a new culture of data teams at Internet startups and corporations that manage larger and larger data sets and want better mechanisms for storage, offline processing and analysis. Many are unhappy with existing solutions; because they solve the wrong problems, are based on ancient storage/processing models, are too expensive, or based on unsuitable infrastructure designs. The ideal computing model in this context is a distributed architecture: if your current system is at its limits you can just add more machines.
One current trend within the Hadoop community is the emergence of processing models on a higher level of abstraction; these usually incorporate a unified model to manage schemas/data structures, and data flow query languages that often bear a striking resemblance to SQL. But they're not trying to imitate relational databases -- e.g. nobody is interested in transactions or low latency. These are offline processing systems.
My personal favourite among these is Facebook's Hive, which could be described as their approach to a data warehousing model on top of MapReduce; it may see an open source release this year (but you never know with these projects.) Then there's Pig, Jaql, and others.
Microsoft has a research project along those lines called Dryad (I think we saw Michael present at one of last year's Google Open Source Jams in London), and I'm quite impressed by their approach. Since they can rely on an existing well-integrated infrastructure they can concentrate on solving the core issues; Dryad implements a execution engine for arbitrary distributed processing systems that self-optimises by transforming a data flow graph and that integrates with their embedded query language Linq. Programs then load data from arbitrary sources (SQL server, file stores, ...).
So Microsoft is already working on much higher levels of abstraction whereas everybody else has to start by first building up some basic infrastructure. It's quite clear that the lack of integration between many of the open source projects in this field results in a duplication of efforts; but there also was a clear aversion among the attendees towards such proprietary systems. (Maybe not surprising at a conference for an open source project.)
I also didn't realise that Yahoo played such a big part in Hadoop development. They obviously regard it a core component of their infrastructure roadmap. Doug Cutting was employed by Yahoo when the project was in its infancy, and 80% of the project's commits are by Yahoo employees. In other words, the biggest beneficiary of Google's publication of the MapReduce paper turned out to be their largest competitor.
Another issue that came up in conversations was the impact a Microsoft/Yahoo merger may have on Yahoo's open source projects -- apparently there is a good chance that MS may decide to switch Yahoo over to their own distributed processing and search infrastructures. (And I wouldn't judge them for it, cf. above.)
Update: Ah, I almost forgot: Last.fm is hiring people to build data warehouses and stuff! :)
Brave. New. Etc
Martin Dittus · 2008-01-01 · a new world, conferences, data mining, drop culture, intellectual property, privacy · write a comment
 |
| Photo by mlcastle, taken at 24c3. |